Idempotency Keys Are Not Just for Payments
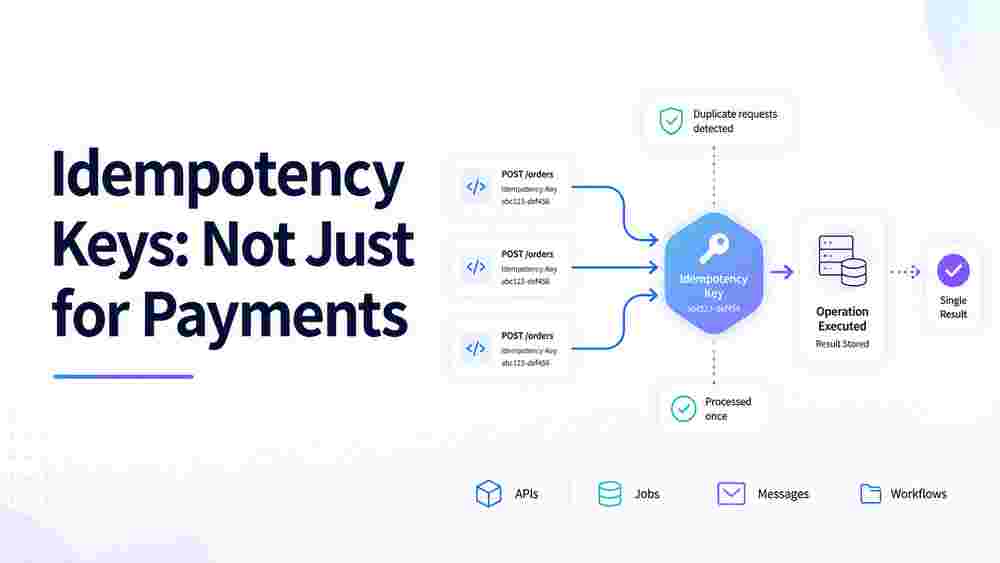
Most engineers I talk to first encounter idempotency keys through Stripe's API, and they walk away with the wrong lesson: that idempotency is a payments thing, a special precaution you take when money is on the line. It is not. Idempotency is a general property you want on any operation that can be retried or delivered more than once, which in a distributed system is almost everything. If your service ingests external events, consumes from a queue, receives webhooks, or just serves a form that a human can submit twice, you have a duplicates problem whether you have noticed it or not. The good news is that the same small pattern solves all of these, and it is not complicated once you see where the duplicates actually come from.
Where duplicates actually come from
Before designing a solution it helps to be honest about the sources, because they are more mundane than people expect:
- Client retries on timeout. A client sends a request, the network stalls, the client gives up at its timeout and retries. But the original request may have arrived and succeeded; the client just never saw the response. Now you have run the operation twice.
- At-least-once queues. Almost every message broker worth using guarantees at-least-once delivery, not exactly-once. If your consumer crashes after doing the work but before acknowledging the message, the broker redelivers it. That is correct behavior on the broker's part. The consumer has to be ready for it.
- Webhook redelivery. Providers retry webhooks aggressively when they do not get a prompt 2xx. A slow response, a deploy mid-request, or a transient error all earn you a second copy of the same event.
- Double-clicks and impatient users. A button that does not disable itself, or a user who is not sure the first click registered, produces two identical requests milliseconds apart.
- Mobile reconnects. Flaky connections mean mobile clients replay in-flight requests when the connection comes back. This is one of the most common real-world sources and the easiest to forget in testing.
The common thread is that the sender cannot tell the difference between "my request was lost" and "my response was lost." Retrying is the rational choice. So the receiver has to be the one that deduplicates.
What makes a good idempotency key
An idempotency key is just a token that uniquely identifies one logical operation. The two big decisions are who generates it and what it covers.
Client-generated vs server-derived. For request-style APIs, the cleanest approach is to let the client generate the key, usually a UUID, and send it in a header like Idempotency-Key. The client knows which of its actions are "the same" far better than the server does, and on a retry the client sends the same key it used the first time. For event ingestion and webhooks you often do not control the sender, but most decent event sources already give you a stable event ID. Use it. If they truly do not, you can derive a key by hashing the meaningful fields of the payload, though that is a fallback, not a first choice.
Scope. A key should be unique within a context, not globally. Scope it to the operation type and the actor: (account_id, "create_invoice", key). This prevents one tenant's key from colliding with another's, and it stops a key meant for one endpoint from accidentally short-circuiting a different one.
What to hash. Alongside the key, store a fingerprint of the request, typically a hash of the normalized body plus the route. The key tells you "this is the same logical operation." The fingerprint lets you detect the dangerous case where someone reuses a key with a different payload.
Storage design
You need a table. It is small and it does a lot of work:
keyplus its scope columns, with a unique constraint across them. This constraint is the entire mechanism; everything else is bookkeeping.request_fingerprintso you can detect mismatched reuse.status, usuallyin_progress,completed, orfailed.response_codeandresponse_bodyso a replay can return exactly what the first call returned.created_atand a TTL or expiry, because these records should not live forever.
The TTL deserves a thought. It needs to be longer than the maximum window in which a legitimate retry can arrive, which for webhook providers can be hours or days. I lean toward 24 hours or more for external sources and shorter for internal request retries. Expire too early and a late retry sails through as a fresh operation, which defeats the purpose.
The race: two identical requests at once
Here is the case that naive implementations get wrong. People reach for "check if the key exists, and if not, do the work." Two identical requests arriving at the same moment both run the check, both see nothing, and both proceed. You have reintroduced the exact duplicate you were trying to prevent, now with a tighter race window that is brutal to reproduce.
The fix is to make the first write atomic and let the database referee. Insert the idempotency row first, before doing the work, and rely on the unique constraint. Exactly one insert wins. The loser catches the constraint violation and, instead of failing, reads the existing row.
INSERT INTO idempotency_keys (scope, key, request_fingerprint, status)
VALUES ($1, $2, $3, 'in_progress')
ON CONFLICT (scope, key) DO NOTHING
RETURNING id;
def handle(request):
fingerprint = hash_request(request)
row = db.execute(INSERT_SQL, scope, request.key, fingerprint).fetchone()
if row is None:
# Someone else owns this key. Read their record.
existing = db.get_idempotency(scope, request.key)
if existing.request_fingerprint != fingerprint:
raise Conflict("Idempotency-Key reused with a different payload")
if existing.status == "in_progress":
# First request is still running; tell the caller to retry shortly.
raise Conflict("Request already in progress", retry_after=2)
return stored_response(existing) # completed: replay the original result
# We won the insert. Do the real work exactly once.
result = do_the_actual_operation(request)
db.complete_idempotency(scope, request.key, result)
return result
The shape that matters: claim the key atomically, do the work only if you won the claim, and persist the result so a future replay can return it. The unique constraint is doing the heavy lifting. No application-level lock, no "check then act" window.
Returning the same response for a replay
A subtle requirement is that a replay should return the same response the original produced, not a freshly computed one. If the first call created invoice number 4012, the retry must return 4012, not create 4013. That is why the stored response lives in the table. When you detect a completed key, you serve the saved status code and body verbatim. The caller cannot tell its retry was a retry, which is exactly what you want.
This also covers stored failures, with a caveat. If the original operation failed in a way that is genuinely permanent, replaying the stored failure is correct. If it failed transiently, you may want to allow a real retry. I usually only persist terminal failures as idempotent results and let transient ones fall through, but that is a judgment call per operation.
Detecting a key reused with a different payload
The fingerprint check earns its keep here. If a key arrives with a body that does not match the stored fingerprint, something is wrong: a client bug, a key generated too coarsely, or two different actions colliding. The safe move is to reject with a 4xx rather than guess. Silently running the new payload would violate the contract, and silently returning the old response would hide a real client bug. Loud failure is the kind thing to do.
Where this lives
The pattern shows up at three layers, and the mechanics are identical at each:
- API layer. Middleware that reads the
Idempotency-Keyheader, wraps the handler, and stores the response. Clients opt in by sending the header. - Job and queue handlers. Use the message ID or a derived key as the idempotency key. This is how you make at-least-once delivery behave like exactly-once processing without lying to yourself about what the broker guarantees.
- Event ingestion. Use the provider's event ID. This is your defense against webhook redelivery and against your own reprocessing during backfills or replays.
In practice I treat exactly-once as a fiction at the transport level and an achievable property at the application level. The transport gives you at-least-once; idempotent handlers turn that into effectively-once. That mental model has saved me from a lot of "but the queue is supposed to handle this" conversations.
The short version
- Idempotency is not a payments feature; it is a requirement for anything retryable or redeliverable.
- Duplicates come from client timeouts, at-least-once queues, webhook redelivery, double-clicks, and mobile reconnects. The sender cannot distinguish a lost request from a lost response, so the receiver must deduplicate.
- A good key is usually client-generated or sourced from a stable event ID, scoped to operation and actor, and paired with a request fingerprint.
- Store key, fingerprint, status, the response, and a TTL longer than your worst-case retry window.
- Handle the race with an atomic insert and a unique constraint, not check-then-act. The first writer wins; the loser reads the stored result.
- Replay the original response verbatim, including the same generated IDs.
- Reject a key reused with a different payload instead of guessing.
- Apply the same pattern at the API layer, in job handlers, and in event ingestion. Transport gives you at-least-once; idempotent handlers give you effectively-once.
Continue reading
Related engineering notes
Jun 22, 2026
ACK, RETRY, DROP: Designing Batch APIs That Survive Bad Networks
All-or-nothing batch endpoints fail badly on mobile and event ingestion. Per-item results - acknowledge, retry, or drop - make clients resilient.
Jun 8, 2026
Shadow Mode Is the Most Underrated Feature Flag
Running new logic in monitor-only mode before you enforce it lets you compare outcomes against production safely - the calmest way to ship risky changes.
Jun 1, 2026
Why Your Worker Needs Its Own Architecture, Not Just process.env.WORKER=true
Splitting an app into API and worker with a single env flag looks clean until idempotency, retries, poison jobs, and deploy shape force a real boundary.