Why Your Worker Needs Its Own Architecture, Not Just process.env.WORKER=true
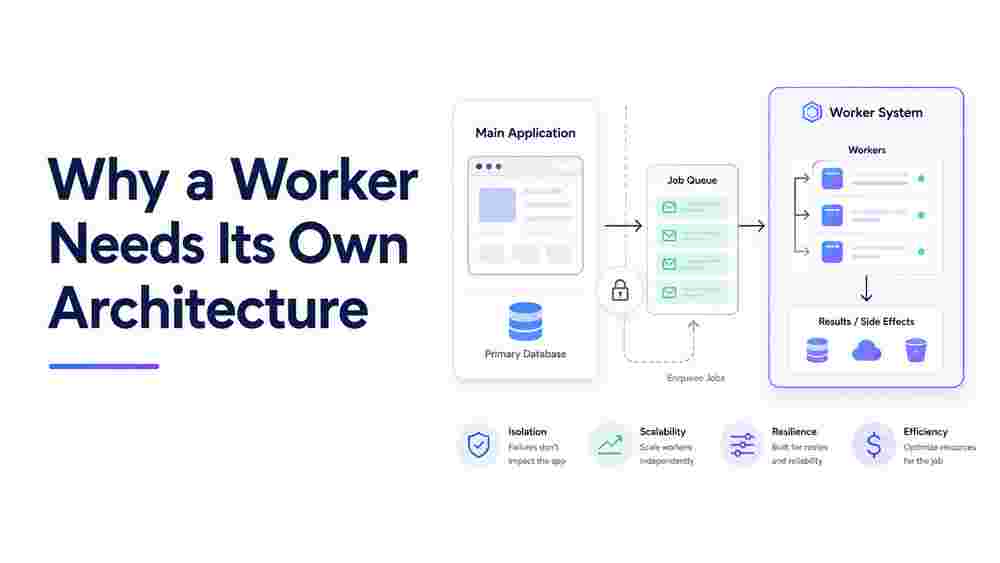
If you run the same codebase as both your API and your background worker, switched by a single process.env.WORKER=true, you do not have two services. You have one service wearing a costume. It works fine until it doesn't, and when it stops working it tends to do so in production, at 2 a.m., with a job that has retried four hundred times. I have shipped this exact pattern, watched it hold up under light load, and then watched it buckle the moment the work got real. This post is about why the env flag feels right, where it breaks, and what an actual worker architecture looks like.
Why the flag feels so reasonable
The appeal is obvious. You already have your domain logic, your database client, your config, your logging. Spinning up a worker means you get to reuse all of it. So you add a branch at the top of your entrypoint:
if (process.env.WORKER === "true") {
startQueueConsumer();
} else {
startHttpServer();
}
Deploy the same image twice, flip the flag on one of them, done. One repo, one build, two roles. For a small app this is genuinely a good call. The mistake is assuming it scales as an architecture rather than as a deployment trick. It is a deployment trick. The problems start when you treat the worker as "the API, but triggered by a queue instead of HTTP."
The API and the worker do not share a lifecycle
An HTTP request is short, bounded, and observed by the caller. If it fails, someone gets a 500 and retries by clicking again. A background job is long, unbounded, and observed by no one in the moment. If it fails, it fails silently unless you built something to notice.
That difference shows up in concrete ways:
- Scaling. Your API scales with concurrent users. Your worker scales with queue depth. These curves are unrelated. A marketing email blast spikes your queue to fifty thousand jobs while your API sits idle. If they share a deployment, you scale the wrong thing.
- Deploy cadence. You want to ship API fixes fast. But deploying mid-job can kill in-flight work. If they are the same deployment, every API hotfix risks dropping a half-finished job.
- Resource profile. API instances want low latency and modest memory. A worker churning through image processing or report generation wants CPU and RAM and does not care about p99. Sharing instance sizing means overpaying for one or starving the other.
None of this is solved by an env flag. The flag gives you one build artifact, which is fine. What you actually need is the ability to scale, deploy, and size the two roles independently, even if they come from the same image.
Shared modules are not automatically safe
This is the subtle one. A module that is perfectly correct inside a request can be quietly wrong inside a worker.
Take a database connection pool sized for request concurrency. In the API, a request grabs a connection, does its work in tens of milliseconds, returns it. In a worker, a single job might hold logic open for thirty seconds while it calls an external API. Same pool, completely different contention. Or take an in-memory cache that assumes a process lives for a request. In a long-running consumer it just grows until the box dies.
The lesson is not "don't share code." It is share domain logic, not runtime assumptions. Your "send invoice" function should live in a shared module. But how it acquires resources, how long it runs, and how it cleans up are worker concerns, and they need to be designed for a process that lives for days.
Jobs run more than once, so handlers must survive it
Here is the rule that separates people who have run queues from people who are about to learn: at-least-once delivery is the default, and exactly-once is mostly a lie. A worker pulls a job, processes it, and crashes before it can acknowledge. The broker, having never heard back, redelivers. Now your "charge the customer" job runs twice.
The fix is not to chase exactly-once semantics. It is to make handlers idempotent so running twice is harmless. The cleanest way is an idempotency key carried on the job and enforced at the boundary where the side effect happens:
async function handleChargeInvoice(job: ChargeInvoiceJob) {
const { invoiceId, idempotencyKey } = job;
// Insert-or-skip on a unique key. If the row already exists,
// this job already ran. Do nothing and acknowledge.
const claimed = await db.idempotency.tryClaim(idempotencyKey);
if (!claimed) return;
const invoice = await invoices.get(invoiceId);
if (invoice.status === "paid") return; // belt and suspenders
await payments.charge(invoice); // the actual side effect
await invoices.markPaid(invoiceId);
}
The tryClaim is a single insert against a unique constraint. Two concurrent deliveries race, one wins, the other is a no-op. The status check is a second line of defense for side effects you do not fully control. Designing this in from the start is far cheaper than retrofitting it after a double-charge incident.
Retries, backoff, and poison jobs
Once jobs retry, you need to decide how. Immediate retries are almost always wrong; if a downstream service is down, retrying instantly just hammers it. Use exponential backoff with jitter so a thundering herd of failed jobs does not all come back at once.
Then there is the job that will never succeed. A malformed payload, a deleted record, a bug in the handler. It fails, retries, fails, retries, forever. This is a poison job, and without a dead-letter strategy it will burn worker capacity indefinitely and bury your logs. The contract should be explicit:
- Cap retries (say, five attempts).
- On the final failure, move the job to a dead-letter queue instead of dropping or re-enqueuing it.
- Alert on dead-letter depth. A growing DLQ is a signal that something systemic broke.
- Make DLQ jobs replayable once the underlying cause is fixed.
I treat the dead-letter queue as a first-class part of the design, not an afterthought. Platforms like Azure Service Bus give you dead-lettering and delivery counts out of the box; if your broker does not, you build the equivalent yourself. Either way, "what happens after the last retry" is a question you answer on day one.
Graceful shutdown and draining
Because deploys and autoscaling kill processes constantly, a worker must shut down without abandoning work. When the process gets a SIGTERM, it should stop pulling new jobs, let in-flight jobs finish within a grace window, acknowledge what completed, and only then exit. Jobs still running when the window closes go back to the queue, which is safe precisely because your handlers are idempotent. The two design choices reinforce each other: idempotency is what makes aggressive shutdown survivable.
Observability is a different shape
A job has no HTTP status code. There is no caller watching a spinner. So the signals you rely on for the API simply do not exist for the worker, and you have to manufacture them:
- Queue depth and age of the oldest message tell you if you are falling behind.
- Processing duration per job type catches slow regressions.
- Retry and dead-letter rates are your real error rate.
- Correlation IDs carried on the payload let you trace a job across services the way a request ID traces an API call.
If your only observability is the API's request dashboard, the worker is a black box.
What the real shape looks like
You can keep one repo and one build. What changes is the structure:
- A separate worker entrypoint, not a branch in the API's bootstrap. Same image is fine; same
main()is not. - Shared domain modules that contain logic, with resource and lifecycle management owned by each runtime.
- Explicit job contracts — a typed payload with an idempotency key, a version, and a correlation ID — instead of passing loose blobs.
- Idempotent handlers enforced at the side-effect boundary.
- A dead-letter strategy with alerting and replay.
- A deploy shape where workers scale on queue depth, independent of API traffic.
The env flag is where this starts. It should not be where it ends.
The short version
process.env.WORKER=trueis a fine deployment trick and a bad architecture.- API and worker have different scaling, deploy cadence, and resource profiles — let them scale independently.
- Share domain logic, not runtime assumptions; request-safe code is not automatically job-safe.
- Assume at-least-once delivery and make every handler idempotent with a key enforced at the side effect.
- Use exponential backoff with jitter, cap retries, and dead-letter poison jobs instead of retrying forever.
- Drain in-flight work on shutdown; idempotency is what makes that safe.
- Build worker-specific observability — queue depth, job duration, retry and DLQ rates, correlation IDs.
Continue reading
Related engineering notes
Jun 22, 2026
ACK, RETRY, DROP: Designing Batch APIs That Survive Bad Networks
All-or-nothing batch endpoints fail badly on mobile and event ingestion. Per-item results - acknowledge, retry, or drop - make clients resilient.
Jun 15, 2026
Idempotency Keys Are Not Just for Payments
External event ingestion, retries, and duplicate submissions all need idempotency. Here is how to design the keys, the storage, and the race handling.
Jun 8, 2026
Shadow Mode Is the Most Underrated Feature Flag
Running new logic in monitor-only mode before you enforce it lets you compare outcomes against production safely - the calmest way to ship risky changes.